Микровычислители
Микросхема содержит два независимых специализированных микровычислителя (CPU1 и CPU2), предназначенных для:
- коррекции статических нелинейностей датчика угла;
- согласования отсчётов в многополюсных датчиках;
- расчёта угловой скорости, ускорения и фильтрации;
- буферизации внутренних сигналов преобразователей.
Наличие двух CPU позволяет одному выполнять коррекцию нелинейностей, а другому — расчёт скорости и ускорения, что обеспечивает средний темп вычислений 50–150 мкс.
Каждый CPU имеет нестандартную разрядность 14 бит, сокращённый набор из 48 команд, 8 регистров общего назначения (R0–R5 по 14 бит, R6 и R7 по 28 бит) и 512 ячеек памяти программ и данных по 14 бит.
Архитектура конвейера
Каждый CPU реализован на основе 4-ступенчатого конвейера:
| Ступень | Назначение |
|---|---|
| IF | Выборка инструкции из памяти по адресу счётчика команд (PC) |
| ID | Декодирование инструкции, чтение регистров |
| EX | Исполнение: АЛУ, CORDIC, умножитель, вычисление адреса, запись в память |
| MEM/WB | Выбор результата, запись в регистр |
Базовое время выполнения одной инструкции — 4 такта FINT. Результат умножения или операции CORDIC может быть готов позже, но не блокирует выполнение следующих инструкций, если они не используют регистры R6 или R7.
Исключения:
- CORDIC (SIN, COS, ATAN) — 16 итераций, ~17 тактов;
- Умножение (MULTI, MULTF и др.) — 5–10 тактов;
- NOP N — N+1 тактов (задержка);
- WAIT_* — блокировка до наступления события.
Регистры общего назначения
| Регистр | Разрядность | Назначение |
|---|---|---|
| R0–R5 | 14 бит | Регистры общего назначения. При чтении знакорасширяются до 28 бит |
| R6 | 28 бит | Результат умножения/сдвига. Всегда перезаписывается командами MULTI, MULTI_ACC, MULTF, MULTF_ACC, MULTCUBE_ACC, DEC2FLOAT |
| R7 | 28 бит | Аккумулятор. Всегда перезаписывается командами ACC, ACC2, MULTI_ACC, MULTF_ACC, MULTCUBE_ACC |
Загрузка и сохранение R6 и R7 возможна только форматами по 28 бит (2 ячейки) или 56 бит (4 ячейки). Загрузить или сохранить только младшие 14 бит R6/R7 нельзя. Для операций с R6/R7 использовать команды LOAD32/STORE32, CLOAD32/CSTORE32.
Структура памяти
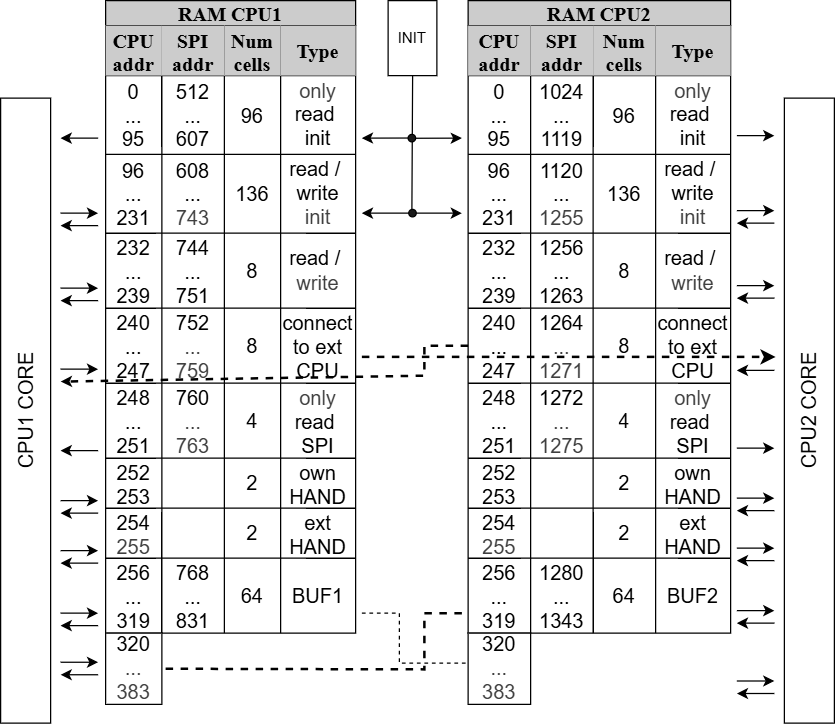
Объём памяти каждого CPU — 512 ячеек по 14 бит. Карта адресов:
| Адреса | Размер | Назначение | Доступ CPU |
|---|---|---|---|
| 0–95 | 96 | Программный код (инструкции) | Только чтение |
| 96–239 | 144 | Данные | Чтение/запись |
| 240–247 | 8 | Обмен между CPU1 и CPU2 | Чтение/запись (кросс) |
| 248–251 | 4 | Ячейки SPI | Чтение/запись |
| 252–253 | 2 | HAND (данные преобразователя) | Чтение/запись |
| 254–255 | 2 | HAND ext (данные внешнего преобразователя) | Чтение/запись |
| 256–383 | 128 | Буфер (BUF) | Чтение/запись |
При включённой функции инициализации (бит INIT_on) в первые 232 ячейки обоих CPU переписываются данные из ПЗУ с последовательным доступом.
Ячейки обмена данными CPU
Ячейки с адресами 240–247 предназначены для передачи данных между CPU1 и CPU2. Шины чтения подключены кросс-образованием: чтение CPU1 по адресам 240–247 возвращает данные, записанные CPU2, и наоборот.
Ячейки обмена с интерфейсом SPI
Ячейки памяти CPU доступны для чтения и записи через интерфейс SPI через регистры Dcpu1LB/Dcpu1HB и Dcpu2LB/Dcpu2HB. Адрес ячейки задаётся в составе транзакции SPI. При записи данные фиксируются в соответствующей ячейке памяти CPU. При чтении возвращается текущее значение ячейки.
Буферы
В микросхему добавлены два дополнительных блока памяти BUF1 и BUF2 по 64 ячейки каждый (адреса 256–319). По умолчанию BUF1 расширяет память CPU1, а BUF2 — CPU2. При необходимости буфер может быть переключён на другой CPU с помощью битов SHRD_RAM и SHRD_CPU2, что позволяет одному CPU работать с 128 дополнительными ячейками (адреса 256–383).
Адресация памяти
Команды загрузки и сохранения используют 7-битное поле адреса. Фактический адрес зависит от типа команды и регистра:
| Команда | Регистр | Ячейки | Диапазон адресов | Формула адреса |
|---|---|---|---|---|
| STORE/CSTORE | R0–R5 | 1 | 128–255 | addr + 128 |
| LOAD/CLOAD | R0–R5 | 1 | 128–255 | addr + 128 |
| STORE32/CSTORE32 | R0–R5 | 2 | 64–318 (чётные) | addr × 2 + 64 |
| LOAD32/CLOAD32 | R0–R5 | 2 | 64–318 (чётные) | addr × 2 + 64 |
| STORE/CSTORE | R6, R7 | 4 | 64–318 (чётные) | addr × 2 + 64 |
| LOAD/CLOAD | R6, R7 | 4 | 64–318 (чётные) | addr × 2 + 64 |
| STORE32/CSTORE32 | R6, R7 | 4 | 64–318 (чётные) | addr × 2 + 64 |
| LOAD32/CLOAD32 | R6, R7 | 4 | 64–318 (чётные) | addr × 2 + 64 |
Для 32-битных операций (STORE32, LOAD32) и операций с R6/R7 адрес всегда умножается на 2. Ячейка с чётным адресом помещается в младшую часть регистра, с нечётным (адрес +1) — в старшую. Для 4-ячеистых операций: {data[addr+3], data[addr+2], data[addr+1], data[addr]}.
Форматы данных
28-битный формат с плавающей запятой
Формат является усечённым IEEE754 float32. Нет NaN, Inf, denormal.
Структура формата
| Поле | Биты | Длина | Описание |
|---|---|---|---|
| Sign | 27 | 1 | 0 = +, 1 = − |
| Exp | 26..20 | 7 | Порядок, bias = 63 |
| Mant | 19..0 | 20 | Мантисса (IEEE754 fraction >> 3) |
Кодирование (Float32 → Float28)
v = single(x)(IEEE754 float32)- Извлечь поля IEEE754:
Sign = bit31,Exp32 = bits30..23,Frac32 = bits22..0 - Порядок: если
Exp32 == 0, тоExp28 = 0, иначеExp28 = Exp32 − 127 Exp = Exp28 + 63Mant = Frac32 >> 3- Упаковка:
Float28 = (Sign << 27) | (Exp << 20) | Mant
Float28 → Float32
- Извлечь:
Sign = bit27,Exp = bits26..20,Mant = bits19..0 - Восстановление:
Exp32 = Exp − 63 + 127,Frac32 = Mant << 3 Value = Sign × (1 + Frac32 / 2^23) × 2^(Exp − 63)
Float28 → Integer
INTvalue = Sign × Mant × 2^(Order - 63), где Sign = +1 если бит 27 = 0, иначе −1.
Система команд
Все инструкции кодируются 14-битным словом. Биты [5:3] кодируют регистр-источник B (SEL_B), биты [2:0] — регистр-приёмник A (SEL_A). Регистры R0–R7 кодируются значениями 000–111.
Арифметико-логические команды
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| NOP | 00000000000 | [N] | Нет операции. При N > 0 — задержка N+1 тактов |
| CLR | 00000000001 | A | A = 0 |
| INC | 00000000010 | A | A = A + 1 |
| DEC | 00000000011 | A | A = A − 1 |
| ABS | 00000000100 | A | A = |A| |
| ACC | 00000000111 | A | R7 = R7 + A |
| ACC2 | 00000001 | B, A | R7 = R7 + A + B |
| ADD | 00000011 | B, A | A = A + B |
| SUB | 00000100 | B, A | A = A − B |
| ORL | 00000101 | B, A | A = A | B |
| ANL | 00000110 | B, A | A = A & B |
| MOVE | 00000111 | B, A | A = B |
| CONST | 1101 | val, A | A = знакорасширенное val (−64…+63) |
Команды сдвига
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| LSL | 000010 | count, A | Логический сдвиг влево: A = A << (count + 1) |
| ASR | 000011 | count, A | Арифметический сдвиг вправо: A = A >> (count + 1) |
Команды умножения и преобразования форматов
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| MULTI | 11110100 | B, A | R6 = A × B (целое, A — 28 бит, B — 24 бит, R6 — 52 бит) |
| MULTI_ACC | 11110101 | B, A | R6 = A × B; R7 = R7 + R6 (целое MAC) |
| MULTF | 11110110 | B, A | R6 = A × B (A — целое 28 бит, B — float 28 бит, R6 — 56 бит) |
| MULTF_ACC | 11110111 | B, A | R6 = A × B; R7 = R7 + R6 (float MAC) |
| MULTK24 | 11111011 | B, A | A = RES[51:22], RES = A × B (целое, 24-битная константа) |
| MULTK14 | 11111100 | B, A | A = RES[40:13], RES = A × B (целое, 14-битная константа) |
| MULTCUBE_ACC | 11111101 | B, A | R6 = (ch1+1)^(ch7+1) × (B + A); R7 = R7 + R6 |
| DEC2FLOAT | 11111110000 | A | R6 = float(A) — преобразование целого в формат float28 |
Команды работы с памятью
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| STORE | 0001 | addr, A | Запись 14 бит: ram[addr] = A[13:0] |
| STORE32 | 0010 | addr, A | Запись 28 бит: ram[addr] = A[13:0], ram[addr+1] = A[27:14] |
| LOAD | 0011 | addr, A | Чтение 14 бит: A = знакорасширение(ram[addr]) |
| LOAD32 | 1100 | addr, A | Чтение 28 бит: A = {ram[addr+1], ram[addr]} |
Индексные команды работы с памятью
Индексные команды CLOAD/CSTORE используют дополнительное смещение rel (см. раздел Канальные регистры). Для работы этих команд необходимо включить режим командой LOADSTORE_ON.
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| CSTORE | 1001 | addr, A | Запись 14 бит: ram[addr + rel] = A[13:0] |
| CSTORE32 | 1010 | addr, A | Запись 28 бит: ram[addr + rel] = A[13:0], ram[addr + rel + 1] = A[27:14] |
| CLOAD | 1000 | addr, A | Чтение 14 бит: A = знакорасширение(ram[addr + rel]) |
| CLOAD32 | 1011 | addr, A | Чтение 28 бит: A = {ram[addr + rel + 1], ram[addr + rel]} |
Команды условного перехода
Все переходы используют относительное смещение от текущего PC.
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| EQUAL | 010 | rel, B, A | PC = PC + rel если A == B (rel: −16…+15) |
| MORE | 011 | rel, B, A | PC = PC + rel если A > B, знаковое (rel: −16…+15) |
| DJNZ | 11100 | rel, A | A = A − 1; PC = PC + rel если A ≠ 0 (rel: −32…+31) |
| CDJNZ | 111010 | rel, CH# | CH# = CH# − 1; PC = PC + rel если CH# ≠ 0 (rel: −16…+15) |
| EQUAL0 | 111011 | rel, A | PC = PC + rel если A == 0 (rel: −16…+15) |
| JUMP | 111100 | rel | PC = PC + rel (rel: −128…+127) |
| RJUMP | 11111111100 | A | PC = A (абсолютный переход по регистру) |
| STOREPC | 11111111101 | A | A = PC + 1 (сохранение адреса возврата) |
CORDIC-команды
Аппаратный CORDIC-сопроцессор выполняет 16 итераций за ~17 тактов. SIN и COS вычисляются одновременно.
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| SIN | 00000000101 | A | Вычисление sin(A). Результат: A = знакорасширенный cordic_sin[15:0]. Аргумент — 18-битный угол (2 старших бита — квадрант) |
| COS | 00000000110 | A | Вычисление cos(A). Результат: A = знакорасширенный cordic_cos[15:0] |
| ATAN | 00000010 | B, A | Вычисление atan2(A, B). Результат: A — 18-битный угол, B — аргумент cos, A — аргумент sin |
Канальные регистры
Канальные регистры используются для индексной адресации памяти и организации циклов.
| Регистр | Разрядность | Команда загрузки | Источник данных |
|---|---|---|---|
| ch0 | 9 бит | CFIX0 | A[8:0] |
| ch1 | 8 бит | CFIX1 | A[7:0] |
| ch2 | 7 бит | CFIX2 | A[6:0] |
| ch3 | 6 бит | CFIX3 | A[5:0] |
| ch4 | 5 бит | CFIX4 | A[4:0] |
| ch7 | 2 бит | CFIX7 | A[1:0] |
Смещение rel для индексных команд вычисляется как взвешенная сумма:
rel = ch0 + ch1 × 2 + ch2 × 4 + ch3 × 8 + ch4 × 16
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| CFIX0 | 11111110100 | A | ch0 = A[8:0] |
| CFIX1 | 11111110101 | A | ch1 = A[7:0] |
| CFIX2 | 11111110110 | A | ch2 = A[6:0] |
| CFIX3 | 11111110111 | A | ch3 = A[5:0] |
| CFIX4 | 11111111000 | A | ch4 = A[4:0] |
| CFIX7 | 11111111001 | A | ch7 = A[1:0] |
| CLR_CH | 11111111010 | CH# | CH# = 0. При CH# = 5 — очистка всех канальных регистров |
| CLOAD_CUBE | 11111111011 | A | A = (ch1+1)^(ch7+1) — полиномиальный базис |
NUMCUBE: значение (ch1+1)^(ch7+1) определяет порядок полинома:
| ch7 | Значение | Базис |
|---|---|---|
| 0 | ch1 + 1 | Линейный |
| 1 | (ch1 + 1)² | Квадратичный |
| 2 | (ch1 + 1)³ | Кубический |
| 3 | 1 | Константа |
Команды управления HAND-интерфейсом
| Команда | Код | Аргументы | Описание |
|---|---|---|---|
| SET_A_HAND | 11111110001 | const | Выбор номера пары ячеек преобразователя (0–7) |
| HFIX | 11111110010 | A | Установка номера HAND из регистра A[2:0] |
Команды управления и синхронизации
| Команда | Код | Описание |
|---|---|---|
| SETB_STP | 11111111110000 | Установка флага STP = 1 |
| CLRB_STP | 11111111110001 | Сброс флага STP = 0 |
| SW_HTE1 | 11111111110010 | Переключение мультиплексора HAND1 на другой CPU |
| SW_HTE2 | 11111111110011 | Переключение мультиплексора HAND2 на другой CPU |
| WAIT_EXT_CPU | 11111111111000 | Ожидание импульса от другого CPU |
| PULSE_EXT_CPU | 11111111111001 | Генерация импульса для другого CPU |
| WAIT_OWN_HAND | 11111111111010 | Ожидание данных от «родного» преобразователя |
| WAIT_EXT_HAND | 11111111111011 | Ожидание данных от «внешнего» преобразователя |
| LOADSTORE_ON | 11111111111100 | Разрешение работы команд CLOAD/CSTORE |
| LOADSTORE_OFF | 11111111111101 | Запрет работы команд CLOAD/CSTORE |
| IDLE | 11111111111111 | Остановка CPU (бесконечный NOP) |
Взаимодействие с преобразователем
Подключение CPU1 и CPU2 к преобразователям (HAND1 и HAND2) осуществляется симметрично: для CPU1 «родным» (own) является HAND1, а внешним (ext) — HAND2. Для CPU2 — наоборот. Считывание данных производится с двойной шириной слова (28 бит): с own по адресам 252–253, с ext по адресам 254–255.
Выбор номера пары ячеек преобразователя выполняется командой SET_A_HAND.
| #ADDR | Содержимое |
|---|---|
| 0 | FullAngle[27:0] |
| 1 | Wca[11:0], BScos[12], ex_shifted, Wsa[11:0], BSsin[12], ex_ref |
| 2 | VirtualS[12:0], ex_recovered, BSsin[12:0], ex_recovered_90dgr |
| 3 | Amp_metric[11:0], Err_metric[15:0] |
| 4 | FullVel[27:0] |
| 5 | PhiC[15:2], PhiS[15:2] |
| 6 | VirtualC[12:0], ex_recovered, BScos[12:0], ex_recovered_90dgr |
| 7 | Pole_addi, STAT |
Запись данных в преобразователь
Доступ к записи в каждый преобразователь есть только у одного CPU. Выбор CPU с доступом на запись определяется конфигурационным битом HandToEXT. CPU может инвертировать действие флага HandToEXT с помощью команд SW_HTE1 и SW_HTE2 (цифра — номер преобразователя).
Запись Coord/Vel
Результаты вычислений CPU могут быть записаны в блок гистерезиса скорости и координаты. Для этого установите флаг Coord_from_cpu или Vel_from_cpu и запишите данные, установив командой SET_A_HAND соответствующий адрес (0 для координаты, 4 для скорости).
Запись Pole_addi
Для записи добавочного значения полюса Pole_addi выставите адрес 3. Запись возможна, если источник определён как CPU с помощью бита PoleAddi_src.
Синхронизация двух CPU
CPU1 и CPU2 могут обмениваться данными и синхронизировать работу:
- Обмен данными — через ячейки 240–247 (кросс-подключение шин чтения).
- Программная синхронизация — WAIT_EXT_CPU ожидает импульс от другого CPU, PULSE_EXT_CPU генерирует импульс.
- Синхронизация с преобразователем — WAIT_OWN_HAND ожидает обновление данных от «родного» преобразователя, WAIT_EXT_HAND — от «внешнего».
- Флаг STP — SETB_STP/CLRB_STP управляют однобитным выходом CPU, может использоваться для внешней сигнализации.
Отладчик
Каждый CPU имеет встроенный отладчик, управляемый через SPI-регистры DBG1_ctrl/DBG1_data и DBG2_ctrl/DBG2_data.
Управление выполнением
Регистр DBG_ctrl:
| Биты | Назначение |
|---|---|
| [12:11] | Команда: 0 = RUN, 1 = STOP, 2 = STEP |
| [10] | Триггер обработки команды (по фронту) |
| [9] | Разрешение точки останова 1 |
| [8:0] | Адрес точки останова 1 |
Регистр DBG_data:
| Биты | Назначение |
|---|---|
| [9] | Разрешение точки останова 2 |
| [8:0] | Адрес точки останова 2 |
Чтение регистров
Чтение внутренних регистров CPU производится через SPI-команду READ_CPU_REGS. Поле sel_reg (биты [13:10]) выбирает данные:
| sel_reg | Данные |
|---|---|
| 0–5 | R0–R5 (14 бит) |
| 6–7 | R6/R7 младшие 14 бит |
| 8–9 | R6/R7 старшие 14 бит |
| 10 | Статус: DBG_STOP, STP, PC, инструкция |
| 11 | Каналы: a_hand, ch1, ch4, ch0 |
| 12 | Каналы: ch7, ch_rel, ch2, ch3 |
Пример программы
CPU1: Коррекция угла по 1-й гармонике
Программа читает угол из преобразователя, вычисляет sin(угол) через CORDIC, умножает на float-коэффициент из памяти и вычитает полученную коррекцию из исходного угла. Результат передаётся CPU2 через ячейки обмена.
SET_A_HAND 0 // Выбрать FullAngle
LOOP: WAIT_OWN_HAND // Ждать обновление данных
LOAD32 HAND1_L R0 // R0 = текущий угол (28 бит, адреса 252-253)
CLR R7 // R7 = 0 (аккумулятор коррекции)
SIN R0 // CORDIC: R0 = sin(угол)
LOAD32 228 R1 // R1 = коэффициент (float28, адреса 228-229)
MULTF_ACC R1 R0 // R6 = R0(целое) × R1(float); R7 += R6
ASR 15 R7 // Масштабирование: R7 >>= 16
MOVE R7 R2 // R2 = коррекция
LOAD32 HAND1_L R0 // R0 = исходный угол (перечитать)
SUB R2 R0 // R0 = угол − коррекция
STORE32 EXTCPU_0 R0 // Исправленный угол → CPU2 (адреса 240-241)
PULSE_EXT_CPU // Сигнал готовности CPU2
JUMP LOOP // Следующий цикл
Используемые переменные (из файла cpu1_ram.txt):
| Переменная | Адрес | Описание |
|---|---|---|
| HAND1_L | 252 | Младшие 14 бит OWN HAND |
| HAND1_H | 253 | Старшие 14 бит OWN HAND |
| EXTCPU_0 | 240 | Младшие 14 бит обмена CPU1→CPU2 |
| EXTCPU_1 | 241 | Старшие 14 бит обмена CPU1→CPU2 |
| (адрес 228) | 228–229 | Float28 коэффициент коррекции |
Пошаговое описание:
SET_A_HAND 0— выбирает пару ячеек FullAngle для чтения из преобразователя.WAIT_OWN_HAND— останавливает CPU до появления новых данных от «родного» преобразователя.LOAD32 HAND1_L R0— загружает 28-битный угол из ячеек 252 (младшие) и 253 (старшие).CLR R7— обнуляет аккумулятор.SIN R0— CORDIC вычисляет sin(R0), результат записывается в R0. CORDIC одновременно вычисляет cos, результат доступен для следующей команды COS.LOAD32 228 R1— загружает 28-битный float-коэффициент из ПЗУ.MULTF_ACC R1 R0— R6 = R0 (целое sin) × R1 (float коэфф.); R7 += R6.ASR 15 R7— арифметический сдвиг R7 вправо на 16 бит (масштабирование накопленной суммы).MOVE R7 R2— R2 = коррекция.LOAD32 HAND1_L R0— перечитывает исходный угол (данные в HAND защёлкнуты).SUB R2 R0— R0 = исходный угол − коррекция.STORE32 EXTCPU_0 R0— записывает 28-битный результат в ячейки 240–241 для CPU2.PULSE_EXT_CPU— генерирует импульс, по которому CPU2 узнаёт о готовности данных.
Сводная таблица команд
| Имя | Код операции | Аргументы | Описание |
|---|---|---|---|
| NOP | 00000000000 | [count] | Нет операции; задержка count+1 тактов |
| CLR | 00000000001 | A | A = 0 |
| INC | 00000000010 | A | A = A + 1 |
| DEC | 00000000011 | A | A = A − 1 |
| ABS | 00000000100 | A | A = |A| |
| SIN | 00000000101 | A | A = sin(A), CORDIC 16 итераций |
| COS | 00000000110 | A | A = cos(A), CORDIC 16 итераций |
| ACC | 00000000111 | A | R7 = R7 + A |
| ACC2 | 00000001 | B, A | R7 = R7 + A + B |
| ATAN | 00000010 | B, A | A = atan2(A, B) |
| ADD | 00000011 | B, A | A = A + B |
| SUB | 00000100 | B, A | A = A − B |
| ORL | 00000101 | B, A | A = A | B |
| ANL | 00000110 | B, A | A = A & B |
| MOVE | 00000111 | B, A | A = B |
| LSL | 000010 | count, A | A = A << (count + 1) |
| ASR | 000011 | count, A | A = A >> (count + 1) |
| STORE | 0001 | addr, A | ram[addr] = A[13:0] |
| STORE32 | 0010 | addr, A | ram[addr..addr+1] = A[27:0] |
| LOAD | 0011 | addr, A | A = знакорасширение(ram[addr]) |
| EQUAL | 010 | rel, B, A | PC += rel если A == B |
| MORE | 011 | rel, B, A | PC += rel если A > B |
| CLOAD | 1000 | addr, A | A = знакорасширение(ram[addr + rel]) |
| CSTORE | 1001 | addr, A | ram[addr + rel] = A[13:0] |
| CSTORE32 | 1010 | addr, A | ram[addr+rel..addr+rel+1] = A[27:0] |
| CLOAD32 | 1011 | addr, A | A = {ram[addr+rel+1], ram[addr+rel]} |
| LOAD32 | 1100 | addr, A | A = {ram[addr+1], ram[addr]} |
| CONST | 1101 | val, A | A = знакорасширение(val), −64…+63 |
| DJNZ | 11100 | rel, A | A--; PC += rel если A ≠ 0 |
| CDJNZ | 111010 | rel, CH# | CH#--; PC += rel если CH# ≠ 0 |
| EQUAL0 | 111011 | rel, A | PC += rel если A == 0 |
| JUMP | 111100 | rel | PC += rel |
| MULTI | 11110100 | B, A | R6 = A × B, целое |
| MULTI_ACC | 11110101 | B, A | R6 = A × B; R7 += R6, целое |
| MULTF | 11110110 | B, A | R6 = A × B, A — целое, B — float |
| MULTF_ACC | 11110111 | B, A | R6 = A × B; R7 += R6, float |
| MULTK24 | 11111011 | B, A | A = (A × B)[51:22] |
| MULTK14 | 11111100 | B, A | A = (A × B)[40:13] |
| MULTCUBE_ACC | 11111101 | B, A | R6 = (ch1+1)^(ch7+1) × (B+A); R7 += R6 |
| DEC2FLOAT | 11111110000 | A | R6 = float(A) |
| SET_A_HAND | 11111110001 | const | Выбор адреса HAND (0–7) |
| HFIX | 11111110010 | A | Установка HAND из A[2:0] |
| CFIX0 | 11111110100 | A | ch0 = A[8:0] |
| CFIX1 | 11111110101 | A | ch1 = A[7:0] |
| CFIX2 | 11111110110 | A | ch2 = A[6:0] |
| CFIX3 | 11111110111 | A | ch3 = A[5:0] |
| CFIX4 | 11111111000 | A | ch4 = A[4:0] |
| CFIX7 | 11111111001 | A | ch7 = A[1:0] |
| CLR_CH | 11111111010 | CH# | CH# = 0; при CH#=5 очистка всех |
| CLOAD_CUBE | 11111111011 | A | A = (ch1+1)^(ch7+1) |
| RJUMP | 11111111100 | A | PC = A |
| STOREPC | 11111111101 | A | A = PC + 1 |
| SETB_STP | 11111111110000 | STP = 1 | |
| CLRB_STP | 11111111110001 | STP = 0 | |
| SW_HTE1 | 11111111110010 | Переключение HAND1 | |
| SW_HTE2 | 11111111110011 | Переключение HAND2 | |
| WAIT_EXT_CPU | 11111111111000 | Ожидание импульса от CPU | |
| PULSE_EXT_CPU | 11111111111001 | Импульс для CPU | |
| WAIT_OWN_HAND | 11111111111010 | Ожидание own HAND | |
| WAIT_EXT_HAND | 11111111111011 | Ожидание ext HAND | |
| LOADSTORE_ON | 11111111111100 | Включить CLOAD/CSTORE | |
| LOADSTORE_OFF | 11111111111101 | Выключить CLOAD/CSTORE | |
| IDLE | 11111111111111 | Остановка CPU |